Data-Driven House Hunting: Finding Our Dream Home
How I built a data platform to transform house hunting from reactive open homes to proactive property identification.
The Starting Point
As many of you know, property is one of my many passions. In fact, I even wrote a guide on buying property in Auckland. Fortunately, my wife shares this enthusiasm.
About a year ago, we made a decision: Auckland is our forever city. With most of our family and friends here, the lifestyle we want, and the quality of life it offers, it felt like the ideal place to settle down and raise a family. So we embarked on a mission to find our dream home—or land to build on—within Auckland, no matter how long it would take, armed with a cheque book and determination.
Between the two of us, we identified about 20 different requirements and criteria. But going to open homes repeatedly and manually evaluating each property was exhausting. That's when I thought: there has to be a better way.
The Data-Driven Approach
To tackle this systematically, I turned to data. Even eliminating half our requirements early would accelerate the search significantly. About half our requirements focused on the house itself, but the other half were about the area and surroundings—things like proximity to neighboring houses, distance to schools, access to public amenities, natural hazards, and more.
With a wealth of open data available from Auckland Council, LINZ, and other sources, I spent a few months building a PostgreSQL database (hosted on Supabase) containing every single property across Auckland, complete with key features:
- Contours and land features
- Natural hazards and risk assessments
- Distance to schools and educational institutions
- Proximity to amenities (shops, Bunnings, parks, etc.)
- Neighborhood density and house spacing
- Zoning and planning permissions
The Technical Challenge
Building this wasn't for the faint of heart. Processing nearly a hundred different data sources—some containing over a million records each—required careful procurement, quality checks, and standardization. I painfully learnt what a CRS (Coordinate Reference System) was and how it differed across various geospatial datasets. I had to go back to my university textbooks to study Big-O time and space complexity to avoid overloading my computer with data processing.
But all the hard work paid off. The database made house hunting dramatically easier, and I knew I could do even more.
From Database to Web Application
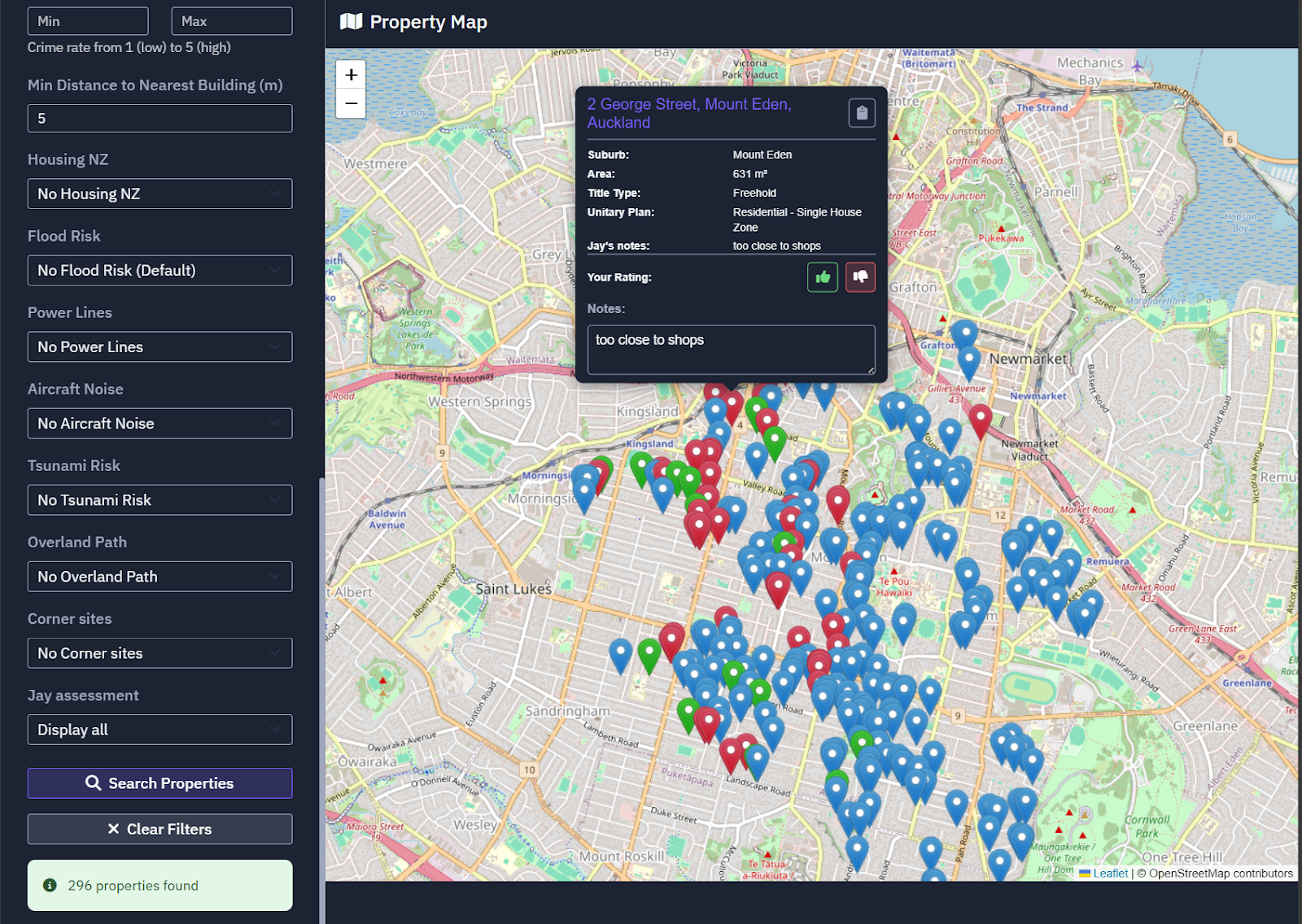
The next phase was building a full web application that lets us search and filter properties based on detailed characteristics. While commercial options like CoreLogic and Re-Leased exist, they're not freely accessible and don't offer the precise filters we wanted—such as proximity to neighbors, avoiding corner properties, or checking specific zoning boundaries.
The app features a collaboration system where my wife and I can add likes, dislikes, and notes on properties. This allows us to evaluate homes together or apart, creating a shared view of our preferences as we narrow down options.
Flipping the House Hunting Process
Instead of reactively attending open homes and hoping something matches our criteria, we're now proactively identifying properties that fit our needs. This fundamental shift in approach has made the entire process significantly more efficient.
We can scroll through properties that already meet our technical requirements, then make strategic decisions about which to visit in person.
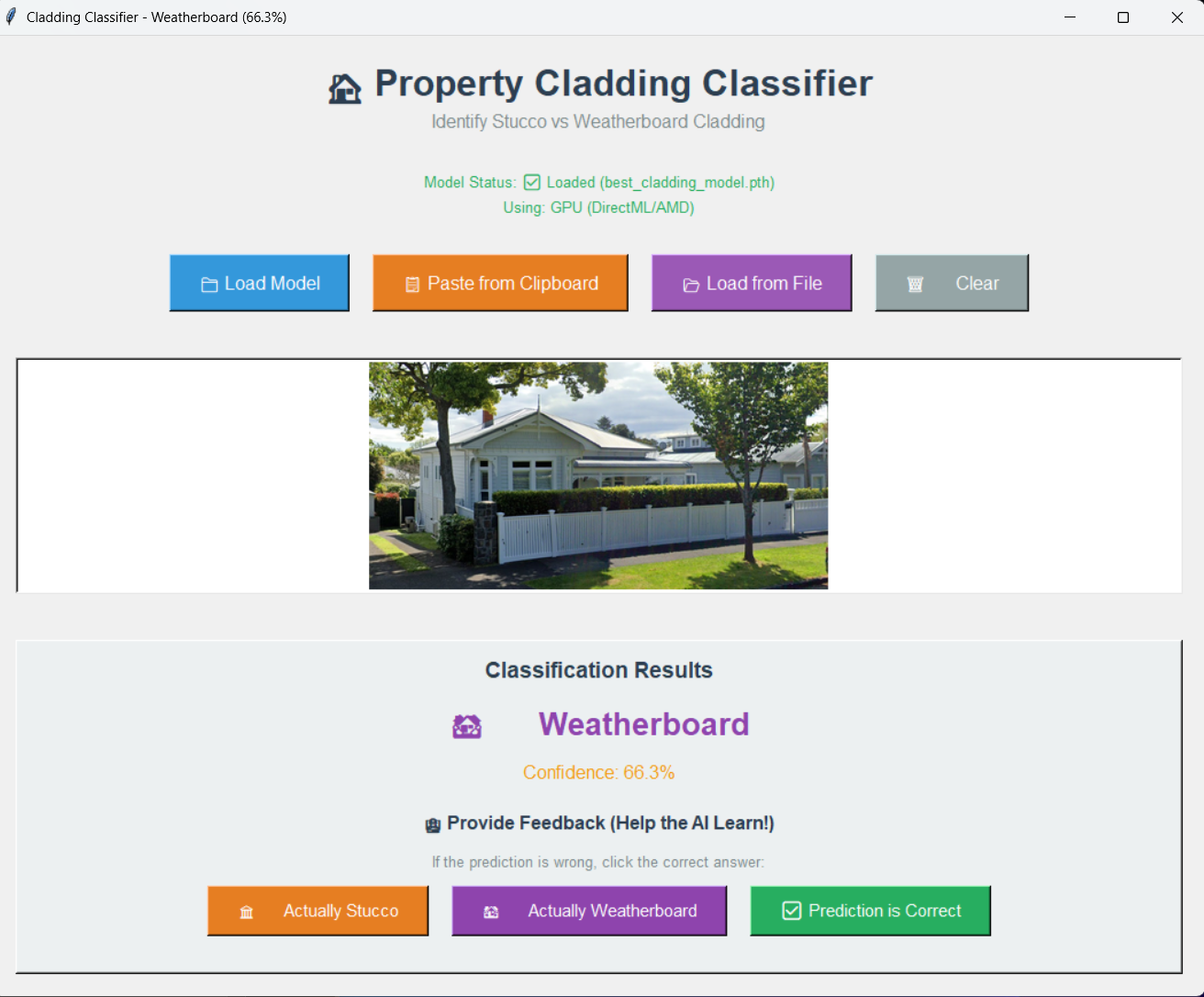
The Next Frontier: Machine Learning
But I'm not stopping there. The next phase is building a machine learning model using Google's Street View API to assess whether properties "look good" based on visual criteria. I'm starting with the basics—identifying cladding types (like Stucco vs. other materials)—and eventually extending it to evaluate whether the front profile of houses matches our aesthetic desires.
This is ongoing work, and I'll be sharing updates as I progress.
The Reality Check
Here's the sobering truth: out of all one million properties in Auckland, there are probably fewer than 300 that we'd seriously consider—and that's without even stepping inside them. The data shows just how selective this process needs to be.
But that's precisely why a data-driven approach works so well. By filtering through millions of properties programmatically, we can focus our time and energy on the houses that genuinely meet our needs, rather than spending weekends at open homes that were never going to work.
Takeaway
This project taught me that when you have a problem with massive optionality, data is your best friend. House hunting, job searching, school selection—these are all problems where applying a structured, data-driven framework can dramatically improve outcomes.